Python中使用Websocket推送bytes数据
有个需求 在直播的时候 如果有人提问 通过LLM回答这个问题并将答案转为音频流返回
考虑直接用Websocket来完成
在fastapi框架下 使用websocket
from fastapi import FastAPI, WebSocket router = FastAPI() @router.websocket("/live/answer") async def live_answer( websocket: WebSocket, ): await websocket.accept()问题用LLM解答
async def process_question(params: AnswerQuestionParams, question): response_stream = await async_openai_obj(streaming=True).chat.completions.create( model=params.llm_setting.model, messages=[ {"role": "system", "content": params.llm_setting.prompt}, {"role": "user", "content": question}, ], stream=True, ) current_sentence = "" async for response in response_stream: choice = response.choices[0] chunk = choice.delta.content or "" current_sentence += chunk while is_complete_sentence(current_sentence): complete_sentence, current_sentence = split_sentence(current_sentence) await queue.put(complete_sentence) await queue.put(END_SIGNAL)将答案转为音频流
async def send_audio(params: AnswerQuestionParams): while True: if queue.empty(): await async_sleep(0.1) continue text = await queue.get() if text == END_SIGNAL: await websocket.send_text(text) break response = await get_openai_async_speech_obj().create( input=text, voice=params.voice, model="tts-1", speed=params.speed, ) await websocket.send_bytes(response.content)
完整代码
import asyncio
from asyncio import sleep as async_sleep
from fastapi import APIRouter, WebSocket, WebSocketDisconnect
from pydantic import BaseModel
from llmbot.clients.llm import async_openai_obj
from llmbot.entities.chatbot_workflow import SimpleLLMSetting
from llmbot.utils.openai_tts import VoiceType, get_openai_async_speech_obj
router = APIRouter()
SPLIT_CHAR = [".", "。", "?", "?", "!", "!"]
END_SIGNAL = "##END##"
QUESTION_PROMPT = """你是一个小助手,擅长解答各种问题。
现在我希望你能帮我回答各种问题。"""
class AnswerQuestionParams(BaseModel):
question: str = ""
llm_setting: SimpleLLMSetting = SimpleLLMSetting(
model="gpt-3.5-turbo",
prompt=QUESTION_PROMPT,
max_tokens=2048,
)
voice: VoiceType = "alloy"
speed: float = 1.0
def is_complete_sentence(sentence: str):
for char in SPLIT_CHAR:
if char in sentence:
return True
return False
def split_sentence(sentence: str):
# 找到第一个。!?的位置,并将句子分割为两部分
for i in range(len(sentence)):
if sentence[i] in SPLIT_CHAR:
return sentence[: i + 1], sentence[i + 1 :]
return "", sentence
@router.websocket("/live/answer")
async def live_answer(
websocket: WebSocket,
):
await websocket.accept()
queue = asyncio.Queue()
async def process_question(params: AnswerQuestionParams, question):
response_stream = await async_openai_obj(streaming=True).chat.completions.create(
model=params.llm_setting.model,
messages=[
{"role": "system", "content": params.llm_setting.prompt},
{"role": "user", "content": question},
],
stream=True,
)
current_sentence = ""
async for response in response_stream:
choice = response.choices[0]
chunk = choice.delta.content or ""
current_sentence += chunk
while is_complete_sentence(current_sentence):
complete_sentence, current_sentence = split_sentence(current_sentence)
await queue.put(complete_sentence)
await queue.put(END_SIGNAL)
async def send_audio(params: AnswerQuestionParams):
while True:
if queue.empty():
await async_sleep(0.1)
continue
text = await queue.get()
if text == END_SIGNAL:
await websocket.send_text(text)
break
response = await get_openai_async_speech_obj().create(
input=text,
voice=params.voice,
model="tts-1",
speed=params.speed,
)
await websocket.send_bytes(response.content)
try:
while True:
input_json: dict = await websocket.receive_json()
if "type" in input_json:
if input_json["type"] == "ping":
await websocket.send_text("pong")
if input_json["type"] == "question":
params = AnswerQuestionParams()
if "prompt" in input_json:
params.llm_setting.prompt = input_json["prompt"]
if "voice" in input_json:
params.voice = input_json["voice"]
if "speed" in input_json:
params.speed = input_json["speed"]
question = input_json["question"]
_ = asyncio.create_task(process_question(params, question))
await send_audio(params)
await async_sleep(0.1)
except WebSocketDisconnect: ...
except Exception: ...
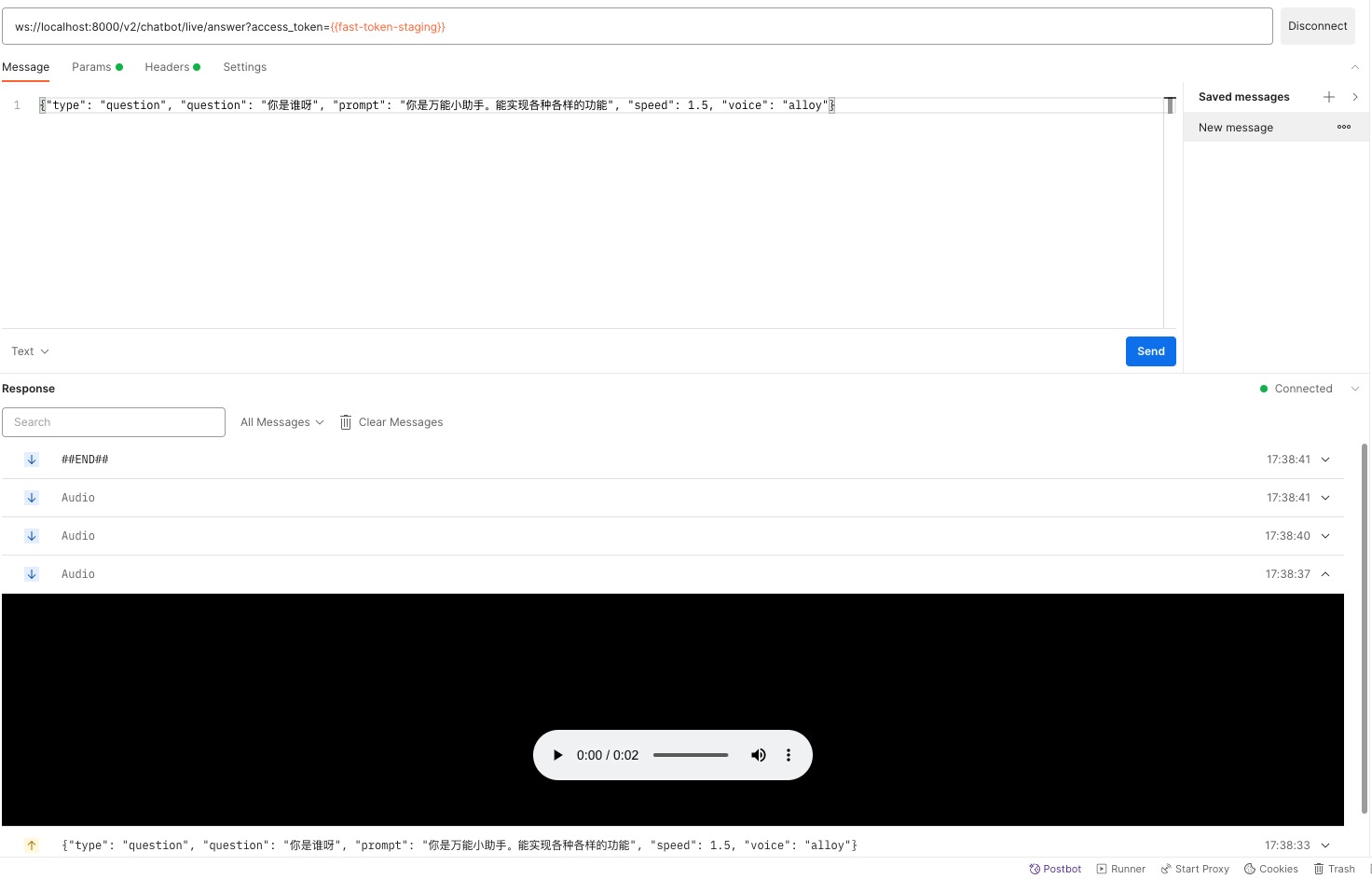
调用结果